By Joseph Carboni
I’ve been taking a course through Codecademy on Machine Learning. Let me tell you, it’s great – worth the money. If there’s one thing I’ve learned so far, it’s that implementing a machine learning model is shockingly easy. Understanding what you want and how to format the data is more challenging than the act of creating the model itself!
Training a Random Forest Classifier
I have an entity matching problem, basically taking a single string that may contain a customer’s name and location, but not always, and I want to match them to customer entities in my database. My fuzzy-matching scheme used for the past year was starting to degrade in performance, and it was only maybe 70% accurate.
So, with 5,000 verified matches, I pulled my correct matches from my database, supplemented it with wrong matches (you want this for training), and used my fuzzy-matching scores (levenshtein, jaro-winkler, etc.) as features. Then I trained a Random Forest Classifier from scikit-learn.
from Levenshtein import ratio, jaro_winkler
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
MAX_CORES = 10
RANDOM_STATE = 42
### data preparation ###
### ... ###
#########################
X = training_data.loc[:,'indel_score':]
y = training_data['is_correct']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=RANDOM_STATE
)
param_grid = {
'n_estimators': list(range(100,1100,100)),
'max_depth': [None, *list(range(100,1100,100))]
}
model = RandomForestClassifier(random_state=RANDOM_STATE)
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
cv=5,
n_jobs=MAX_CORES,
verbose=2,
scoring='accuracy'
)
grid_search.fit(X_train, y_train)
best_rf = grid_search.best_estimator_
There’s a lot going on here. I used parameter grid search to train the Random Forest model over and over again with different settings for hyperparameters in param_grid: the number of estimators and maximum tree depth. 5-fold Cross validation was also used.
One drawback to Scikit-learn is that you can’t offload it to the GPU like you can with other libraries out there. However, you can multithread it on the CPU, which is what I did here with MAX_CORES set to 10 and passed into GridSearchCV. Training took only a couple minutes, and then I extracted the best estimator, which scored 92% accuracy!
Now what?
So I’ve got a Random Forest model estimator, now what do I do with it?
First, save it to a file using joblib, which comes with scikit-learn.
import joblib
joblib.dump(best_rf, 'rf_model.joblib')
Now to deploy it. One thing you won’t want to underestimate is how big these files can get. Github wouldn’t even let me commit it without some sort of “big file” plan. There are ways to trim them down, but for the sake of this example lets take it as-is. I put this model file into another project and put it behind a bare-bones Flask API.
One endpoint for model features, and one for ingesting string-matching data to make a prediction with.
from asgiref.wsgi import WsgiToAsgi
from flask import Flask, jsonify, request
import pandas as pd
import numpy as np
import joblib
from sklearn.ensemble import RandomForestClassifier
from os import getenv
from dotenv import load_dotenv
load_dotenv()
MODEL_PREDICTION_THRESHOLD = float(getenv('MODEL_PREDICTION_THRESHOLD'))
RF_MODEL: RandomForestClassifier = joblib.load(getenv('MODEL_LOCATION'))
app = Flask(__name__)
@app.route('/cmmssns/entity-matching/model-features', methods=['GET'])
def cmmssns_model_features():
features = list(RF_MODEL.feature_names_in_)
return jsonify({"data": features})
@app.route('/cmmssns/entity-matching', methods=['POST'])
def cmmssns_predict():
model_features = list(RF_MODEL.feature_names_in_)
## assuming the data comes in 'split' orientation
df = pd.DataFrame(**request.get_json())
# predict
predictions = RF_MODEL.predict_proba(X=df.loc[:, model_features])[:, 1]
df["predictions"] = np.where(
predictions >= MODEL_PREDICTION_THRESHOLD, predictions, 0)
max_score = df["predictions"].max()
if max_score == 0:
result = 0
else:
cb_id: pd.Series = df.loc[df["predictions"] == max_score, "branch_id"]
if len(cb_id) == 1:
result = cb_id.item()
else:
result = int(cb_id.iloc[0])
result_json = jsonify({"result": result})
return result_json
asgi_app = WsgiToAsgi(app)
As you can see, just import it and use it! The RF_MODEL’s predict_proba() method is used to generate probabilities that the string scores are indicative of a match, then the best one is picked.
On the consumer side, I logged out some statements so I could see it in action. There’s really nothing quite so satisfying.
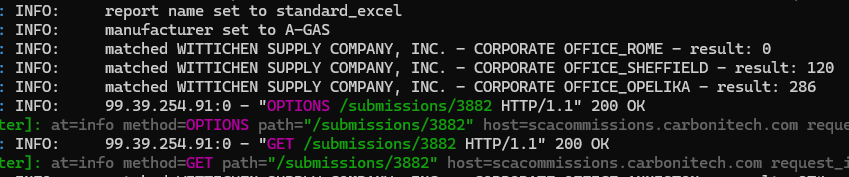
The ones it matched (non-zero) were right on, like this one.

ABOUT THE AUTHOR
Joseph Carboni is a multifaceted programmer with a background in bioinformatics, neuroscience, and sales, now focusing on Python development. He developed a ribosomal loading model and contributed to a neuroscience paper before transitioning to a six-year sales career, enhancing his understanding of business and client relations. Currently, he’s a Python Developer at Shupe, Carboni & Associates, improving business processes, and runs Carboni Technology for independent tech projects. Joseph welcomes collaborations and discussions via LinkedIn (Joseph Carboni), Twitter (@JoeCarboni1), or email (joe@carbonitech.com).
PUBLISH YOUR WRITINGS HERE!
We are always looking to publish your writings on the pyATL website. All content must be related to Python, non-commercial (pitches), and comply with out code of conduct.
If you’re interested, reach out to the editors at hello@pyatl.dev